



Next: Vertex Weighted Graph Partitioning
Up: OPOSSUM
Previous: OPOSSUM
Contents
Balancing
Typically, one segments transactional data into 7-14 groups, each of
which should be of comparable importance. Balancing avoids trivial
clusterings (e.g., 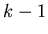 singletons and 1 big cluster). More
importantly, the desired balancing properties have many application
driven advantages. For example when each cluster contains the same
number of customers, discovered phenomena (e.g. frequent products,
co-purchases) have equal significance / support and are thus easier to
evaluate. When each customer cluster equals the same revenue share,
marketing can spend an equal amount of attention and budget to each of
the groups.
OPOSSUM strives to deliver `balanced' clusters using
either of the following two criteria:
singletons and 1 big cluster). More
importantly, the desired balancing properties have many application
driven advantages. For example when each cluster contains the same
number of customers, discovered phenomena (e.g. frequent products,
co-purchases) have equal significance / support and are thus easier to
evaluate. When each customer cluster equals the same revenue share,
marketing can spend an equal amount of attention and budget to each of
the groups.
OPOSSUM strives to deliver `balanced' clusters using
either of the following two criteria:
- Sample balanced: Each cluster should contain roughly the same
number of samples,
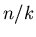 . This allows, for example, retail marketers
to obtain a customer segmentation with equally sized customer groups.
. This allows, for example, retail marketers
to obtain a customer segmentation with equally sized customer groups.
- Value balanced: Each cluster should contain roughly the
same amount of feature values. Thus, a cluster represents a
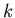 -th
fraction of the total feature value
-th
fraction of the total feature value
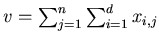 . In customer clustering, we use extended price per product
as features and, thus, each cluster represents a roughly equal
contribution to total revenue. In web-session clustering the feature
of choice is the time spent on a particular web-page. This results in
user clusters balanced with respect to the total time spent on the
site.
. In customer clustering, we use extended price per product
as features and, thus, each cluster represents a roughly equal
contribution to total revenue. In web-session clustering the feature
of choice is the time spent on a particular web-page. This results in
user clusters balanced with respect to the total time spent on the
site.
We formulate the desired balancing properties by assigning each object
(customer, document, web-session) a weight and then softly constrain
the sum of weights in each cluster. For sample balanced clustering,
we assign each sample
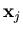 the same weight
the same weight 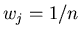 . To
obtain value balancing properties, a sample
's weight is
set to
. To
obtain value balancing properties, a sample
's weight is
set to
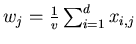 . Please note that the
sum of weights for all samples is 1.
. Please note that the
sum of weights for all samples is 1.
Next: Vertex Weighted Graph Partitioning
Up: OPOSSUM
Previous: OPOSSUM
Contents
Alexander Strehl
2002-05-03