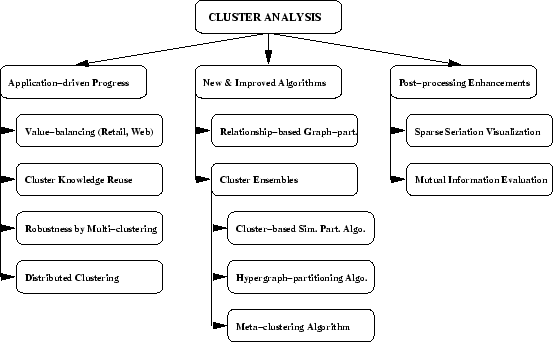
In this dissertation, cluster analysis was extended in several directions driven by information-rich, complex data. Real-life objects are often characterized by an abundance of features as well as taxonomies from a variety of views and times. The main contributions of this dissertation are summarized in figure 6.1. The contributions are organized along three areas of cluster analysis activities, namely applications, algorithms, and result assessment.
Transactional shopping records motivated us to develop better analysis
tools than the available tools such as a-priori association rule
mining or ![]() -means. We developed a relationship-based clustering
framework that relies only on pairwise similarities to side-step the
curse of dimensionality. In this spirit, we developed an intuitive
clustering visualization using sparse seriation of the pairwise
similarity matrix. We improved similarity measures by proposing and
analyzing an extended Jaccard similarity measure. In the retail
domain, we also introduced application-driven constraints of value-balancing to cluster analysis (e.g., clusters have
approximately equal total revenue or number of customers). These
constraints turned out to be useful in a variety of other domains
such as clustering web-sessions and text documents.
-means. We developed a relationship-based clustering
framework that relies only on pairwise similarities to side-step the
curse of dimensionality. In this spirit, we developed an intuitive
clustering visualization using sparse seriation of the pairwise
similarity matrix. We improved similarity measures by proposing and
analyzing an extended Jaccard similarity measure. In the retail
domain, we also introduced application-driven constraints of value-balancing to cluster analysis (e.g., clusters have
approximately equal total revenue or number of customers). These
constraints turned out to be useful in a variety of other domains
such as clustering web-sessions and text documents.
In our work with text document data, the availability of human engineered document taxonomies inspired a clustering performance evaluation measure based on mutual information. The results obtained through this framework showed that relationship-based clustering is indeed superior when appropriate domain-specific similarities are chosen.
When a multitude of taxonomies is already present, one might just want to reuse such existing knowledge and integrate previous results instead of starting from scratch. This led us to develop cluster ensembles, an approach to adopt multi-learner systems for clustering. We proposed a formal cluster ensemble problem and developed three effective and efficient algorithms to solve it. This combiner framework is useful in a variety of applications besides knowledge reuse. For example, it enables distributed clustering and can provide robustness through multiple clusterings.