



Next: Contributions
Up: Introduction
Previous: Relationship-based Clustering Approach
Contents
Many traditional clustering techniques [Har75,Nie81,JD88] do
not perform satisfactorily in data mining scenarios due to a
variety of reasons. These reasons can be divided into those arising from the
data distribution and those caused by application constraints:
- Data Distribution
- Large number of samples.
- The number of samples to be processed
is very high. Algorithms have to be very conscious of scaling
issues. Like many interesting problems, clustering in general is NP-hard, and
practical and successful data mining algorithms usually scale linear or
log-linear. Quadratic and cubic scaling may also be allowable but a
linear behavior is highly desirable.
- High dimensionality.
- The number of features is very high and
may even exceed the number of samples. So one has to face the
curse of dimensionality [Fri94].
- Sparsity.
- Most features are zero for most samples, i.e. the
object-feature matrix is sparse. This property strongly affects the
measurements of similarity and the computational complexity.
- Strong non-Gaussian distribution of feature values.
- The
data is so skewed that it can not be safely modeled by normal
distributions.
- Significant outliers.
- Outliers may have significant importance.
Finding these outliers is highly non-trivial, and removing them is
not necessarily desirable.
- Application context
- Legacy clusterings.
- Previous cluster analysis results are
often available. This knowledge should be reused instead of
starting each analysis from scratch.
- Distributed data.
- Large systems often have heterogeneous
distributed data sources. Local cluster analysis results have to be
integrated into global models.
For example, in market-basket analysis and text document clustering,
we found the number of samples ranging from 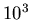 to
to 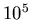 , each
sample having around to attributes. On average, over
99% of the attributes are zero, resulting in a very non-Gaussian
feature value distribution. In fact, the distribution is often modeled
best by a Poisson with a point mass at 0.
Outliers are often present and important, such as restaurant owners in
grocery shopping records, or index pages in document clustering.
, each
sample having around to attributes. On average, over
99% of the attributes are zero, resulting in a very non-Gaussian
feature value distribution. In fact, the distribution is often modeled
best by a Poisson with a point mass at 0.
Outliers are often present and important, such as restaurant owners in
grocery shopping records, or index pages in document clustering.
In the document clustering application context, a multitude of legacy
clusterings is available from several sources, such as Yahoo!, DMOZ,
or Northern Light, which can be exploited for current analysis.
The new challenges of high-dimensional, large-scale, heterogeneous
databases create the need for new approaches to clustering.
Next: Contributions
Up: Introduction
Previous: Relationship-based Clustering Approach
Contents
Alexander Strehl
2002-05-03