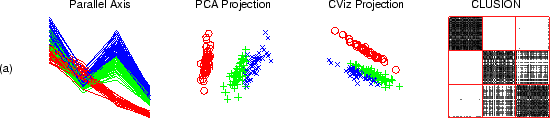
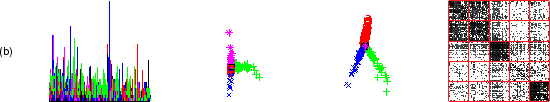
|
| cluster | dominant category | purity | entropy | most frequent word stems |
| 1 | health (H) | 100% | 0.00 | hiv, depress, immun |
| 2 | health (H) | 100% | 0.00 | weight, infant, babi |
| 3 | online (o) | 58% | 0.43 | apple, intel, electron |
| 4 | film (f) | 38% | 0.72 | hbo, ali, alan |
| 5 | television (t) | 83% | 0.26 | household, sitcom, timeslot |