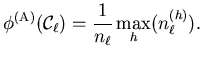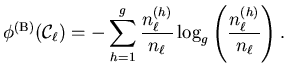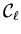 |
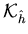 |
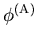 |
 |
|
1 |
P |
21.05% |
0.73 |
|
2 |
H |
91.48% |
0.15 |
|
3 |
S |
68.39% |
0.40 |
|
4 |
P |
52.84% |
0.60 |
|
5 |
T |
63.79% |
0.39 |
|
6 |
o |
57.63% |
0.40 |
|
7 |
B |
60.23% |
0.48 |
|
8 |
f |
37.93% |
0.66 |
|
9 |
cu |
50.85% |
0.48 |
|
10 |
p |
36.21% |
0.56 |
|
11 |
f |
67.80% |
0.33 |
|
12 |
f |
77.59% |
0.31 |
|
13 |
r |
47.28% |
0.56 |
|
14 |
mu |
44.07% |
0.56 |
|
15 |
p |
50.00% |
0.50 |
|
16 |
mu |
18.97% |
0.71 |
|
17 |
p |
55.08% |
0.54 |
|
18 |
t |
82.76% |
0.24 |
|
19 |
f |
38.79% |
0.58 |
|
20 |
f |
69.49% |
0.36 |
|
|
top 3 descriptive terms |
|
israel, teeth, dental |
|
breast, smok, surgeri |
|
smith, player, coach |
|
republ, committe, reform |
| java, sun, card |
|
apple, intel, electron |
|
cent, quarter, rose |
|
hbo, ali, alan |
|
bestsell, weekli, hardcov |
|
albert, nomin, winner |
|
miramax, chri, novel |
|
cast, shoot, indie |
|
showbiz, sound, band |
|
concert, artist, miami |
|
notabl, venic, classic |
|
fashion, sold, bbc |
|
funer, crash, royal |
|
househ, sitcom, timeslot |
| king, japanes, movi |
|
weekend, ticket, gross |
|
|
top 3 discriminative terms |
|
mckinnei, prostat, weizman |
|
symptom, protein, vitamin |
|
hingi, touchdown, rodman |
|
icke, veto, teamster |
|
nader, wireless, lucent |
|
pentium, ibm, compaq |
|
dow, ahmanson, greenspan |
|
phillip, lange, wendi |
|
hardcov, chicken, bestsell |
|
forcibl, meredith, sportscast |
|
cusack, cameron, man |
|
juliett, showtim, cast |
|
dialogu, prodigi, submiss |
|
bing, calla, goethe |
|
stamp, skelton, espn |
|
poetri, versac, worn |
|
spencer, funer, manslaught |
|
timeslot, slot, household |
|
denot, winfrei, atop |
|
weekend, gross, mimic |
|