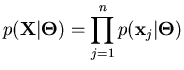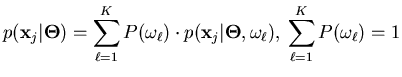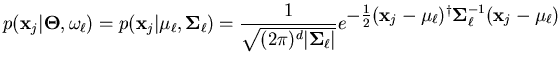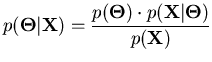In statistical pattern recognition, the data is considered as a set of
observations from a parametric probability
distribution. [Fuk72,DH73]. In a two stage process, the
parameters
![]() of the relevant distributions are learned and later applied to predict the behavior or origin of
a new observation. In Maximum Likelihood (ML) estimation,
the parameters
of the relevant distributions are learned and later applied to predict the behavior or origin of
a new observation. In Maximum Likelihood (ML) estimation,
the parameters
![]() are chosen such that the
probability of the observed samples
are chosen such that the
probability of the observed samples
![]() is maximized.
is maximized.
If there is domain knowledge or a desired behavior of the parameter
![]() 's distribution, Bayes' learning should be used instead of the
ML estimation.
's distribution, Bayes' learning should be used instead of the
ML estimation.
The learned distributions
![]() can now be used for categorization and prediction of a sample's cluster
label. The Bayes classifier is optimal in
terms of prediction error, assuming that the distribution of the data is known
precisely:
can now be used for categorization and prediction of a sample's cluster
label. The Bayes classifier is optimal in
terms of prediction error, assuming that the distribution of the data is known
precisely:
Often, using the log-likelihood (equation 2.15) instead of the actual probability values has advantages for optimization (e.g., convexity, products of very small probabilities which may be problematic for fixed precision numerics are avoided).
The theory behind statistical models is very well understood and
explicit computations of error bounds are advantageous. Statistical
formulations are advantageous for soft clustering problems with a
moderate number of dimensions ![]() . The very powerful
Expectation-Maximization (EM) algorithm [DLR77]
has been applied to
. The very powerful
Expectation-Maximization (EM) algorithm [DLR77]
has been applied to ![]() -means [FRB98]. However, these
parametric models tend to impose structure on the data, that may not
be there. The selected distribution family may not be really
appropriate. In fact, high-dimensional data as found in data mining is
distributed strongly non-Gaussian. Also, the number of parameters
increases rapidly with
-means [FRB98]. However, these
parametric models tend to impose structure on the data, that may not
be there. The selected distribution family may not be really
appropriate. In fact, high-dimensional data as found in data mining is
distributed strongly non-Gaussian. Also, the number of parameters
increases rapidly with ![]() so that the estimation problem becomes more
and more ill-posed. Non-parametric models, like
so that the estimation problem becomes more
and more ill-posed. Non-parametric models, like ![]() -nearest-neighbor,
have been found preferable in many tasks where a lot of data is
available.
-nearest-neighbor,
have been found preferable in many tasks where a lot of data is
available.