Essentially, if two objects are in the same cluster then they are
considered to be fully similar, and if not they are dissimilar. This
is the simplest heuristic and is used in the Cluster-based Similarity
Partitioning Algorithm (CSPA). With this viewpoint, one can simply
reverse engineer a single clustering into a binary similarity matrix.
Similarity between two objects is 1 if they are in the same cluster
and 0 otherwise.
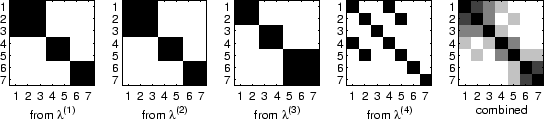
For each clustering, a
![]() binary similarity matrix is
created. The entry-wise average of
binary similarity matrix is
created. The entry-wise average of ![]() such matrices representing the
such matrices representing the ![]() sets of groupings yields an overall similarity matrix.
Figure 5.3 illustrates the generation of the
cluster-based similarity matrix for the example given in table
5.1.
sets of groupings yields an overall similarity matrix.
Figure 5.3 illustrates the generation of the
cluster-based similarity matrix for the example given in table
5.1.
Alternatively, and more concisely, this can be interpreted as using
![]() binary cluster membership features and defining similarity as
the fraction of clusterings in which two objects are in the same
cluster. The entire
binary cluster membership features and defining similarity as
the fraction of clusterings in which two objects are in the same
cluster. The entire
![]() similarity matrix
similarity matrix
![]() can be
computed in one sparse matrix multiplication
can be
computed in one sparse matrix multiplication
![]() .5.4
.5.4
Now, we can use the similarity matrix to recluster the objects using any reasonable similarity based clustering algorithm. We chose to partition the induced similarity graph (vertex = object, edge weight = similarity) using METIS [KK98a] because of its robust and scalable properties.
|