The Fruits of Misunderstanding, EWD 854, May 1983
- ... spaces1.2
- A similar overview on spaces in classification problems can be found e.g. in [Kum00]
- ... Muller2.1
- In
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
The Uses of the Past, 1952
- ... soft2.2
- In
soft clustering, a record can belong to multiple clusters with
different degrees of `association' [KG99].
- ... 100).2.3
-
For text mining, linearly projecting down to about 20-50 dimensions
does not affect results much (e.g., LSI). However,
it is still too high to visualize. A projection to lower dimensions
leads to substantial degradation and 3-dimensional projections are of
very limited utility.
- ... Barnard3.1
- In
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Printers' Ink, March 1927
- ... items3.2
- This is the dilution effect described in
[GRS99].
- ...
regions3.3
- This can be more clearly seen in the color pictures
in the soft-copy.
- ... drugstore3.4
- provided by Knowledge
Discovery 1
- ... revenue3.5
- The solution for
 -means depends on the
initial choices for the means. A representative solution is shown
here.
-means depends on the
initial choices for the means. A representative solution is shown
here.
- ... Gau\ss4.1
- Quoted in A. Arber,
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
The Mind and the Eye, 1954
- ...
high-dimensional4.2
-
The dimension of a document in vector space representation is the size
of the vocabulary, often in the tens of thousands.
- ... generated.4.3
- IBM Patent Server has over 20 million
patents. Lexis-Nexis contains over 1 billion documents
- ... results.4.4
- Often, data abstraction has to
performed between clustering and final assessment [JD88].
- ... balanced.4.5
- There are other ways of
normalizing mutual information such that the best possible labeling
evaluates to 1 even when the categorization is not balanced. However,
these tend to biased towards high . Details can be found in
appendices B.1 and B.2.
- ... information.4.6
-
Let
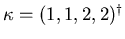 ,
,
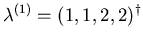 ,
and
,
and
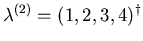 .
.
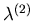 is an over-refinement of correct clustering
is an over-refinement of correct clustering
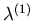 .
The mutual information between
.
The mutual information between 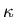 and
is 2
and the mutual information between and
is 2, also.
Our [0,1]-normalized mutual information measure
and
is 2
and the mutual information between and
is 2, also.
Our [0,1]-normalized mutual information measure
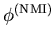 penalizes the useless refinement:
penalizes the useless refinement:
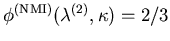 which is less than
which is less than
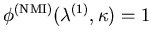 .
.
- ... result.4.7
-
For verification purposes we also computed
entropy values for our experiments and compared with e.g.,
[ZK01] to ensure validity.
- ...
HGP).4.8
- Intersections of performance curves in classification
(learning curves) have been studied recently e.g., in [PPS01].
- ... Aristotle5.1
- In
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Metaphysica
- ...
disjoint5.2
-
The methods can be extended to combine soft
clusterings, wherein an object can belong to multiple clusters with
different degrees of `association'.
- ...ta:supra_clustering_example.5.3
-
When generalizing our algorithms to soft clustering,
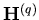 simply contains the posterior probabilities of cluster
membership.
simply contains the posterior probabilities of cluster
membership.
- ....5.4
-
This approach can be extended to soft clusterings
through using the objects' posterior probabilities cluster
of cluster membership in
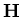 .
.
- ... meta-cluster.5.5
-
A weighted average can be used if the initial clusterings have
associated confidences as in soft clustering.
- ....5.6
-
Labels were drawn from a uniform distribution from 1 to . Therefore,
groups are approximately balanced.
- ... settings.5.7
- In low noise
settings, the original labels are the global maximum, since they share
the most mutual information with the distorted labelings.
- ... visualization.5.8
-
Using a greater number of clusters than categories can be viewed as
allowing multi-modal distributions for each category. For example, in
a noisy XOR problem, there are two categories, but four clusters.
- ...
clustering.5.9
- For the purpose of this discussion, the best
clustering is equivalent to the categorization.
- ... feature-map5.10
-
In fact, the self-organizing feature-map yielded sub-random quality.
This is due to the fact that it produced incoherent as well as
imbalanced clusters.
- ... consensus5.11
- When features are available as in
previously considered distributed data mining scenarios [KPHJ99], one can
e.g., merge partitions based on their centroids to reach consensus.
- ....5.12
-
Overlap assures that the meta-graph in MCLA is connected, e.g. a path between any pair of hyperedges/clusters exists.
- ...
function.5.13
- CSPA is
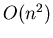 and would reduce speedups obtained by
distribution.
and would reduce speedups obtained by
distribution.
- ... Einstein6.1
- In interview given aboard the liner
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
Belgenland, New York, December 1930
- ... Miller7.1
- In speech on Annual Seminar of the
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . .